

The Business Pressure: Competing Against a Household-Name Giant
A personal care brand launched a sulfate-free body wash on Amazon US. On paper, the product sat in a high-potential space: clean beauty, gender-neutral positioning, and a popular coconut-vanilla scent.
Yet performance stalled.
The team was under pressure for very concrete reasons:
- A category-leading competitor—backed by a global household name—dominated the same search terms.
- The competitor’s product page clearly outperformed theirs in click-through and conversion.
- Internal discussions kept circling the same conclusion:
“We just need more reviews and higher star ratings to catch up.”
They were wrong.
DeepBI’s diagnostics showed that reviews were not the primary constraint. The real issue was buried in how the listing told its story—or rather, how it failed to tell one at all.

---
The Original Misdiagnosis: Blaming Social Proof for a Structural Weakness
Before using DeepBI, the customer team framed the problem like this:
- The competitor had over 80,000 reviews and a 4.8 rating.
- Their own listing had about 600 reviews and a 4.6 rating.
- Therefore:
“We’re losing because they have social proof and we don’t.”
The intuitive “solution” they gravitated to:
- Push harder on review volume.
- Run more promotions to encourage feedback.
- Consider discounting to drive volume first, fix conversion later.
In other words: treat the symptom (fewer reviews) as the root cause.
What they didn’t see was that their listing structure was fundamentally underbuilt compared to the competitor. The review gap was real, but it wasn’t the first bottleneck.
---
What DeepBI’s Score Exposed: The Hidden 24-Point Hole
DeepBI’s listing scoring didn’t start with opinion; it started with a benchmark.
For this product, DeepBI locked onto a directly comparable category-leading competitor as the benchmark (similar product form, similar audience, same core benefits).
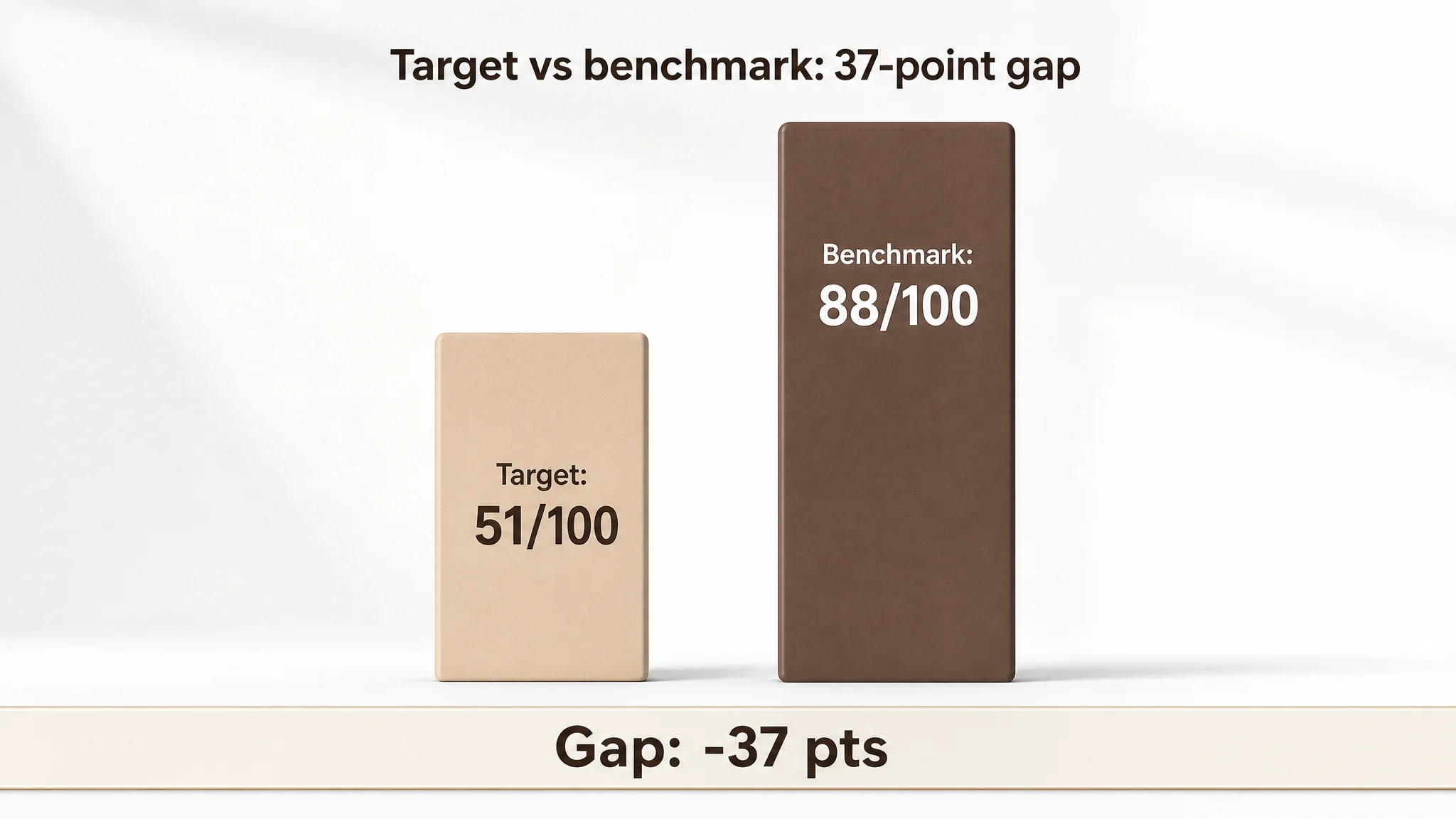
The cold numbers:
- Target listing total score: 51 / 100
- Benchmark listing total score: 88 / 100
- Gap: -37 points
At first glance, every dimension looked “a bit behind but not catastrophic”—except one:
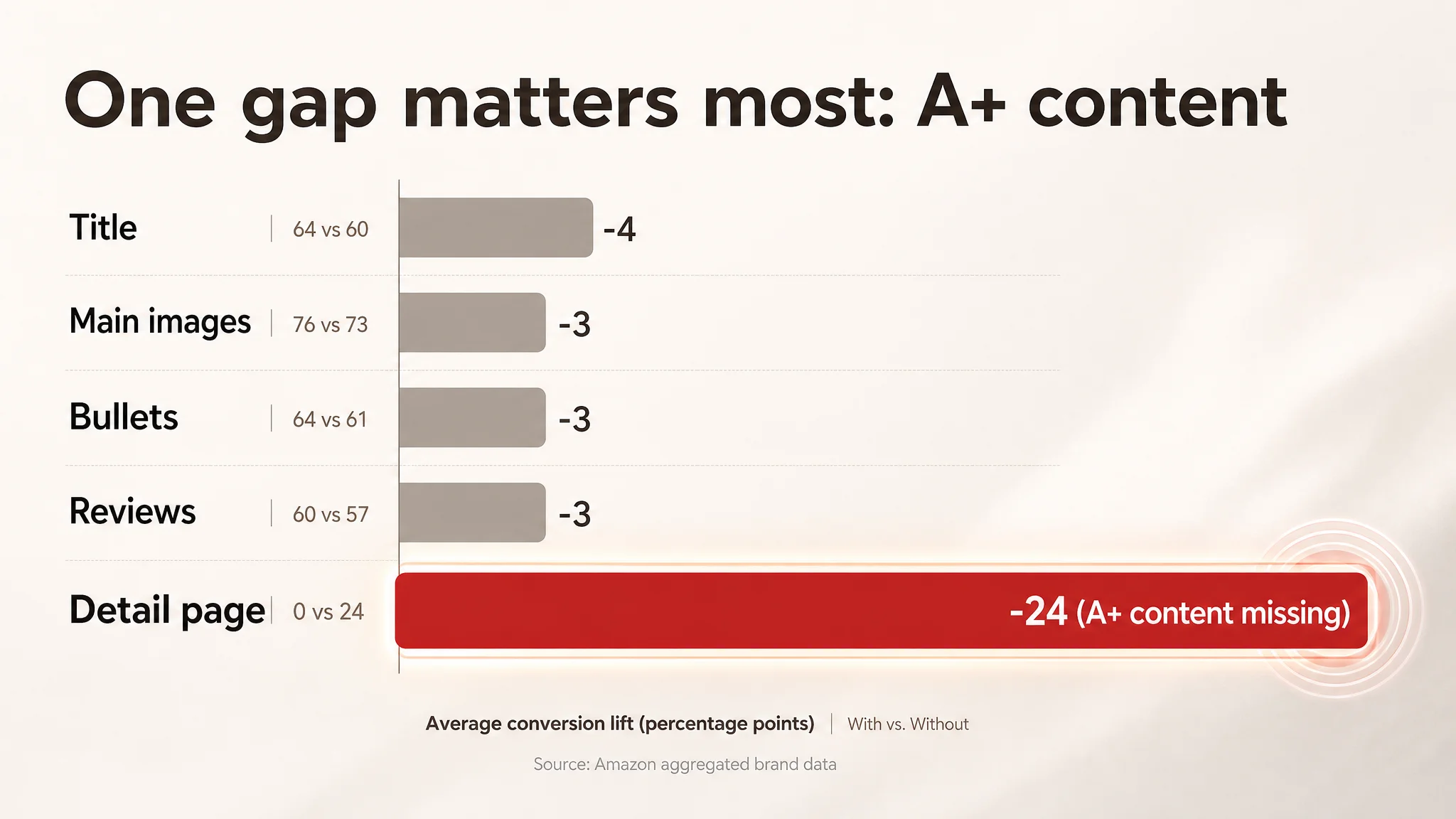
| Dimension | Target Listing | Benchmark | Max | Gap | |-----------|----------------|-----------|-----|-----| | Title | 11 | 15 | 20 | -4 | | Main Images | 23 | 26 | 30 | -3 | | Bullet Points | 6 | 9 | 10 | -3 | | Detail Page (A+) | 0 | 24 | 25 | -24 | | Reviews | 11 | 14 | 15 | -3 |
The largest single gap—24 points out of 25—was not reviews, not main images, not the title.
It was the detail page (A+), where the target listing had effectively nothing.
In a category where the competitor used a fully built A+ layout—core benefits, awards, technical story, ethical positioning, Q&A, and brand narrative—the target listing left a blank space.
This changed the entire diagnostic conversation.
Instead of “we’re losing because shoppers don’t trust us yet,” the data said:
> “Shoppers never get the chance to trust you because your page stops talking halfway.”
---
How the Benchmark Revealed the Real Constraint
DeepBI did not simply say “A+ is missing, add A+.” It decomposed how the benchmark used its detail page and how that affected buyer judgment.
1. The Benchmark’s Detail Page Structure
The competitor’s A+ content wasn’t just decoration. It followed a deliberate sequence:
- Core Benefit Hero Module
- Full-bleed visual
- Prominent award badges (e.g., beauty awards, dermatologist recommendations)
- Simple, result-oriented promise (24-hour moisture, lotion-soft skin)
- Fragrance & Texture Module
- Close-up visuals of foam and texture
- Fragrance notes explained in simple, sensory language
- Technology & Safety Module
- Short explanation of the moisturizing technology
- Clear “free from” claims (no sulfates, no parabens)
- Credible certifications (e.g., PETA, dermatologist tested)
- Sustainability & Ethics Module
- Recycled packaging, biodegradable formula
- Vegan / cruelty-free positioning
- Q&A Trust Reinforcement Module
- Anticipated questions:
- “Can I use this on my face?”
- “Is it suitable for sensitive skin?”
- Direct, reassuring answers that shorten the decision time
Each module closed a different psychological gap: “Does it work?” → “Is it safe?” → “Is it aligned with my values?” → “Is it right for my specific skin?”

2. The Target Listing’s Detail Page: A Void
The target body wash listing had:
- No A+ content.
- No structured brand narrative.
- No visualized proof of awards, certifications, or technology.
- No pre-emptive Q&A to address doubts around sensitive skin, residue, or use cases.
DeepBI’s scoring framework treated this as more than a design omission. It was a direct conversion risk:
- Shoppers who clicked (at least partially thanks to the product’s reasonable main image and title) reached a thin page.
- Those already primed by the category leader’s rich storytelling had higher expectations by default.
- Without supporting content, the target listing forced them to either:
- Leave to read more reviews (stretching the decision path), or
- Back out to the search page and reconsider the category leader.
This is why DeepBI assigned a near-zero score on detail page richness. The constraint wasn’t “not enough proof overall”; it was “proof exists but is trapped in text and reviews, not in the page structure where it can do its job.”
---
Why “Fix the Obvious First” Was Not the Right Priority
Most teams would have started with:
- “Let’s improve the star rating.”
- “Let’s redesign the main image.”
- “Let’s rewrite the bullets.”
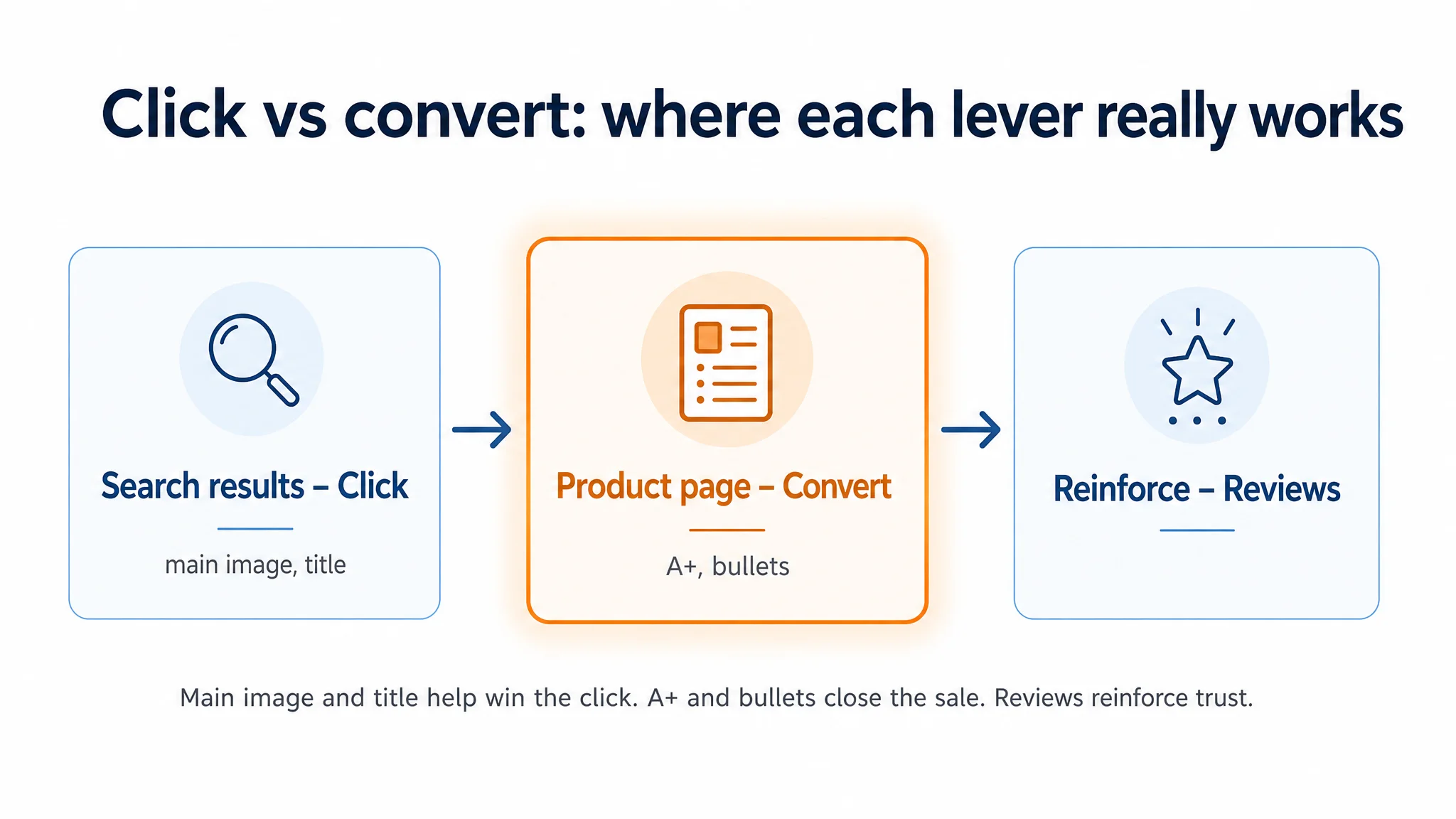
All of those matter—but DeepBI’s scoring showed where each lever actually sits in the decision path:
- Main image → affects click (CTR) at the search result stage.
- Title & bullets → affect both click (through keywording) and initial trust.
- Detail page/A+ → primarily affects conversion (CVR) once the shopper is already on-page.
- Reviews → reinforce or compensate for the above; they are not a standalone replacement for missing structure.
For this listing, the numbers were clear:
- Main image gap: -3
- Title gap: -4
- Bullets gap: -3
- Reviews gap: -3
- Detail page gap: -24
DeepBI’s rationale was:
> “You are not yet limited by marginal differences in star rating or minor title tweaks. You are limited by the absence of the decision architecture that your competitor uses to convert.”
In other words:
- If you chase more reviews first, you pay for more traffic into an underbuilt page.
- If you tweak only the main image, you may pay for more clicks without improving the on-page story.
- If you do everything at once without priority, you diffuse effort and still may not fix the primary constraint.
So the action order DeepBI suggested was:
- Build a functioning A+ decision path
- So traffic has somewhere to convert.
- Reframe the title and bullets to align with how the category leader structures promises.
- Then refine main images to strengthen click competitiveness.
- Treat reviews as a long-term compounding asset, not a band-aid.
This order is rational because it follows the funnel:
- Fix conversion architecture first so existing traffic can be monetized better.
- Then increase the quality and volume of traffic.
- Let reviews grow on top of a page that deserves them.
---
Rebuilding the Listing’s Narrative: What Actually Changed
DeepBI’s role was not to “make the listing prettier”. It was to translate the benchmark’s logic into a tailored structure for this specific brand and product.
1. Title: From “Ingredient List” to Outcome-Focused Promise
Original pattern (simplified):
- Ingredient focus + audience + clean label claims
→ Heavy on what’s inside, light on what it does.
Benchmark pattern:
- Brand + core outcome (24hr lotion-soft skin) + product form (“body wash”, “skin cleanser”) + secondary claims (no sulfates, no parabens)
DeepBI’s diagnostic conclusion:
- The title underused high-intent, outcome-focused search language like “moisturizing”, “skin cleanser”, “soft skin”.
- It emphasized “sulfate free” but didn’t connect that to a benefit (e.g., gentleness, non-stripping cleansing).
- It lacked the structure buyers already recognize in this category.
Resulting title logic:
> Brand + “Sulfate Free Body Wash” + “Naturally Derived Ingredients” + “Moisturizing Skin Cleanser” + Unisex positioning + Signature scent + “Paraben Free” + Size
This was not just keyword stuffing. It repositioned the product from “a nice-smelling wash” to:
- A moisturizing skin cleanser
- With clean-beauty credentials
- For both women and men
It aligned with how the category leader framed its product while preserving the brand’s clean formula angle.

2. Bullet Points: From Parallel Claims to a Persuasion Ladder
DeepBI compared bullets line-by-line against the benchmark and identified a logic gap:
- Benchmark:
“Award & technology → long-lasting effect → ingredient mechanism → problem-specific solutions → ethical & environmental positioning.”
- Target:
“Core benefit → scent description → awards → sub-category awards → ingredient safety.”
On paper, both mention awards, benefits, and safety. In practice, the benchmark:
- Opens with authority (beauty awards, dermatologist recommendation).
- Explains how it works (technology story).
- Spells out for whom and for what problems.
- Ends with values (vegan, cruelty-free, recyclable bottles).
DeepBI’s recommendation was to reorganize and sharpen bullets so they each carried a specific job in the decision process:
- Authority + Core Benefit
- Lead with credible awards (e.g., “Best Scented Body Wash”) and tie directly to skin feel and longevity.
- Sensory Experience
- Elevate the scent beyond “coconut & vanilla” into a “tropical escape” narrative that supports emotional positioning.
- Professional Endorsement
- Use existing recognition (e.g., men’s grooming awards) to frame the formula as a dermatologist-recommended choice, especially for male buyers.
- Differentiated Skin Feel
- Directly differentiate from the competitor’s “lotion-soft” afterfeel by emphasizing a residue-free, squeaky-clean finish for shoppers who dislike “coated” skin.
- Clean Beauty & Ethics
- Summarize “no sulfates, no parabens, no dyes, no phthalates” under a “Thoughtfully Made & Clean” statement, connecting formulation choices to skin health and values.
The important shift: bullets stopped being five disconnected claims and became a laddered argument:
> “You can trust this → it feels amazing → experts back it → it solves your specific preference (no residue) → it fits your clean, ethical standards.”

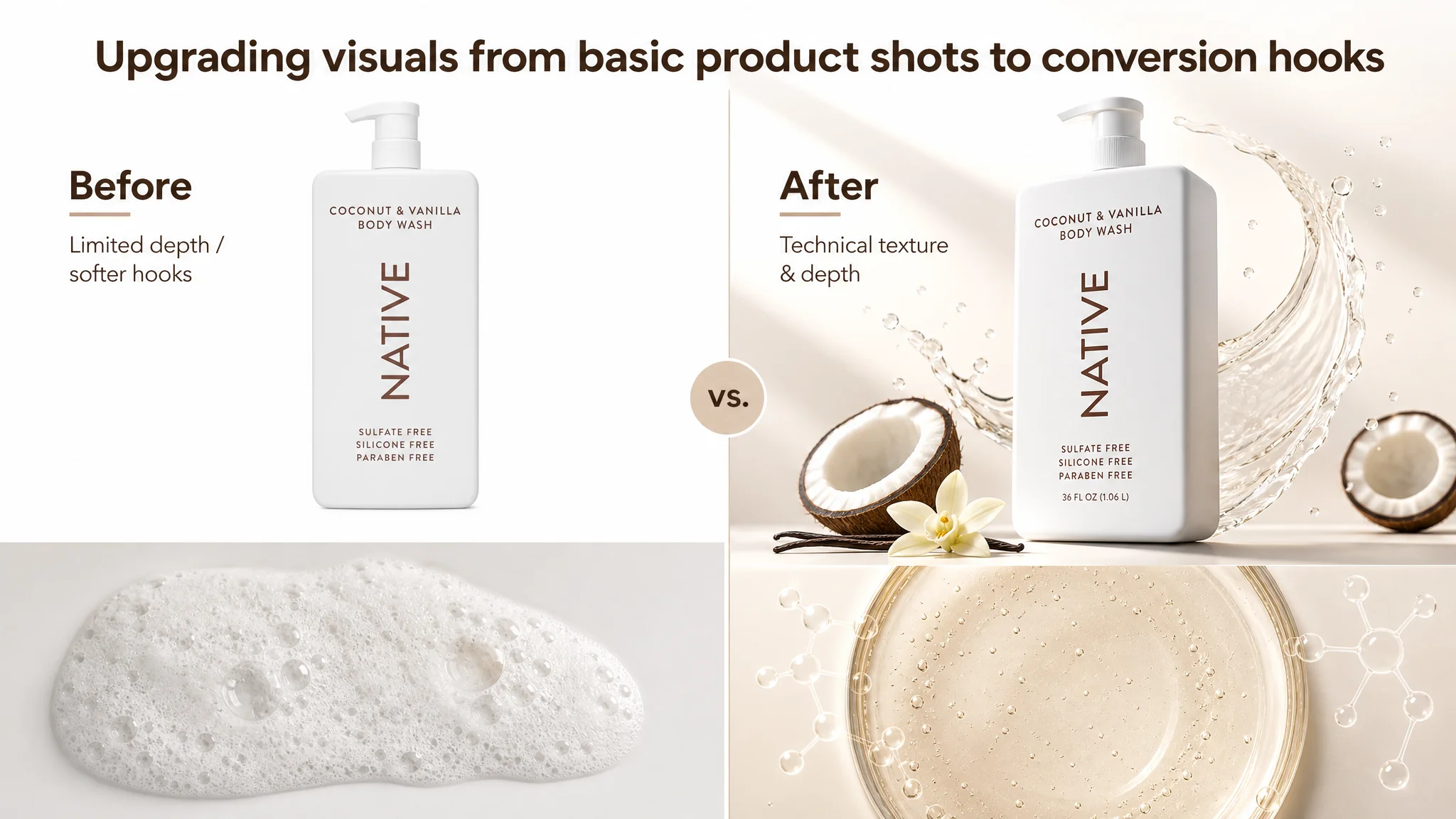
3. Main Images: From Generic Visuals to Category-Standard Hooks
DeepBI’s image diagnostics compared each main image slot against the benchmark:
- Where the benchmark used:
- Bottle hero shots with award badges
- High-contrast, recognizable brand colors
- Foam and texture macros
- Ingredient storytelling scenes
- The target listing:
- Showed the product
- Hinted at clean-beauty aesthetics
- But lacked strong hooks, technical visuals, or trust elements
DeepBI’s guidance was highly specific, not abstract:
- Vary angles (slight side angle hero shot to build depth).
- Introduce an in-bathroom scene with subtle tiled background and foam to signal “real use”.
- Add a liquid texture macro to visually confirm a clear, clean formula consistent with “sulfate free”.
- Use ingredients imagery (coconut, vanilla flower) to materialize the scent story.
- Reserve clear space for simple textual badges (e.g., “#1 Clean Brand”) without clutter.
This was not about copying the benchmark’s style. It was about:
- Matching the information density that buyers expect in this category.
- Aligning visual story (clean, residue-free, gender-neutral) with textual claims.
4. Detail Page (A+): From Zero to a Functional Decision Flow
The most critical change was conceptual: the team shifted from “we don’t have A+, we’re busy” to “this is where our conversion is leaking.”
While DeepBI didn’t have their original A+ (because it didn’t exist), it could clearly map what was missing by contrasting with the benchmark:
- No hero module detailing core benefit and awards.
- No explanation of “naturally derived ingredients” beyond a tagline.
- No callout of clean-beauty credentials in a visual format.
- No Q&A addressing face use, sensitive skin, or residue concerns.
- No brand story or values articulation.
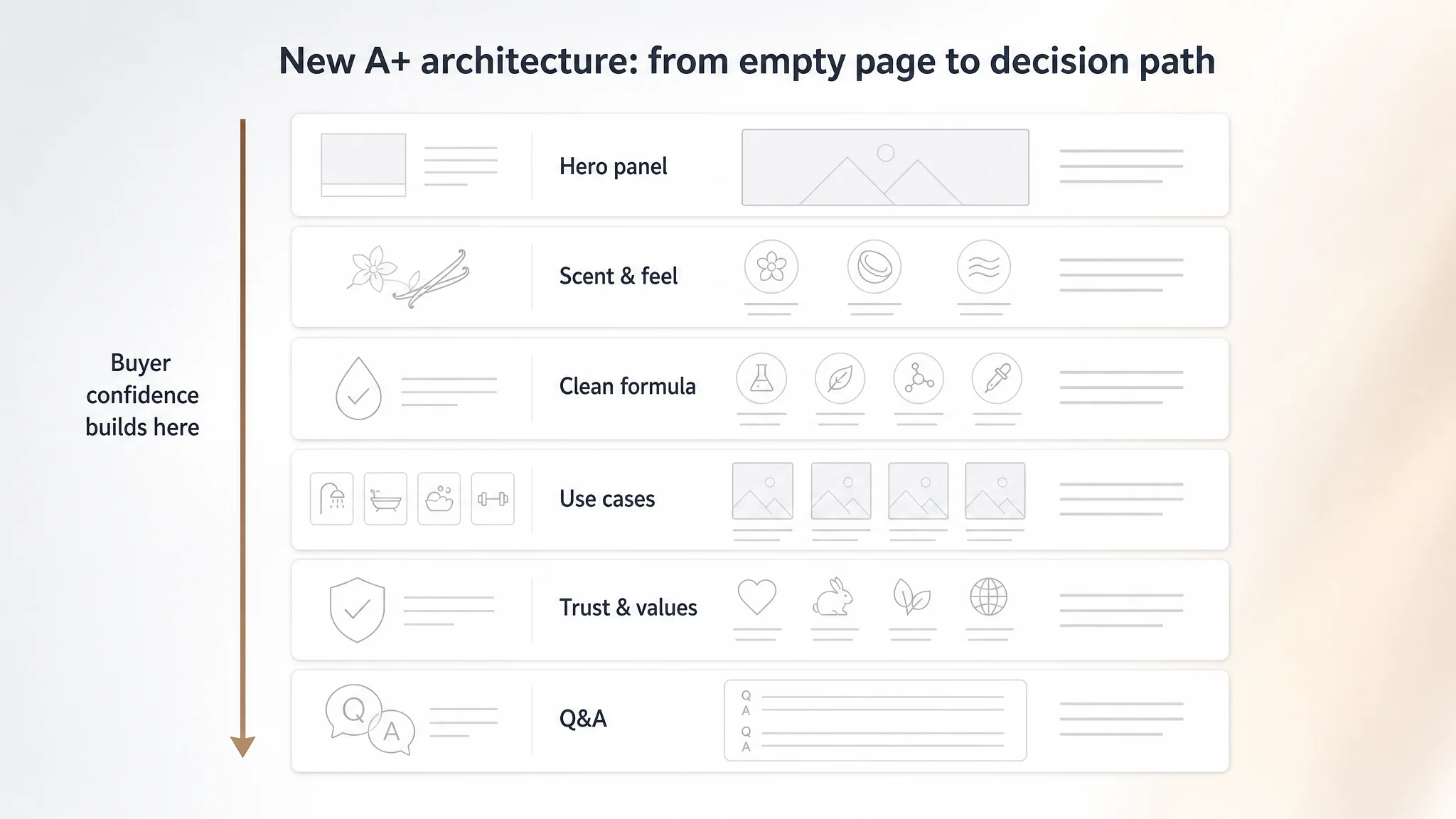
The operating change was therefore less about a single graphic and more about a page architecture:
- Hero Panel:
- Full-width bottle imagery
- Awards and key claim (residue-free clean with long-lasting freshness)
- Scent & Feel Panel:
- Visual representation of the scent profile
- Side-by-side explanation: “Residue-free vs lotion-like feel”
- Clean Formula Panel:
- High-clarity icons for “no sulfates, no parabens, no dyes, no phthalates”
- A short “why it matters” explanation in plain language
- Use Case Panel:
- Clear statement on who it’s for (women & men, normal to sensitive skin)
- Guidance on how often to use, any compatibility notes (e.g., shaving, shaving prep)
- Trust & Values Panel:
- Any available certifications (cruelty-free, etc.)
- Reference to eco-conscious choices if applicable
- Q&A Panel:
- Pre-emptively answer the top hesitation questions the competitor already addresses.
Even without finalized post-implementation data, the shift in design logic was substantial:
- From a single layer (image + bullets + reviews)
- To a multi-layer structure that reinforces each claim visually and textually.
---
What Changed in the Team’s Operating Understanding
DeepBI’s biggest contribution in this case was not a particular line of copy or a specific image layout. It was a change in how the team interpreted their own performance problems.
1. From “We Need More Social Proof” to “We Need a Decision Architecture”
Before:
- Social proof (reviews) was seen as the main missing piece.
- A+ was treated as a “nice to have”, delayed behind other priorities.
After DeepBI’s diagnosis:
- The team understood that:
- Their review quality was already strong (4.6 average, mostly 4–5 stars on the first page).
- The competitor actually showcased a 1-star review on the first page but still outperformed due to sheer volume and a better-structured page.
- They realized:
- Reviews were amplifiers, not a substitute for missing core content.
- Their biggest controllable gap was structural—the absence of A+ modules and a coherent persuasion flow.
2. From Aesthetic Tweaks to Competitive Benchmarks
Before:
- Image and text changes were driven by internal taste and ad-hoc ideas.
- There was no quantified sense of “how far behind” they were in each dimension.
After DeepBI:
- They had a numerical breakdown:
- Where they were close (main image, title, bullets, reviews).
- Where they were severely behind (detail page).
- This changed internal debates:
- From “I think our images are fine” vs “We should redesign”
- To “We’re 24 points behind on detail page; that’s our primary value gap.”

3. From One-Off Fixes to Funnel-Based Priorities
Before:
- Optimization actions were considered atomically (change X, see what happens).
- There was no consistent order: sometimes images first, sometimes price, sometimes copy.
After DeepBI:
- The team started to think in terms of:
- Click lever (main image, title)
- Conversion lever (A+, bullets, trust modules)
- Long-term credibility lever (reviews)
The immediate plan shifted to:
- Build A+ content to catch up the 24-point gap.
- Align title and bullets with benchmark-proven structures (outcome first, then supporting evidence).
- Iterate main images with clearer hooks and texture visualization.
- Allow reviews to compound on top of a more effective page.
---
Conclusion: DeepBI as a Business Diagnosis Engine, Not a Feature List
In this case, DeepBI’s value was not that it generated copy, images, or a certain score.
Its value was:
- Isolating the real constraint: a 24-point gap in detail page structure, not a vague “lack of trust” or “not enough reviews”.
- Translating competitor advantage into a specific decision architecture the team could adopt without imitating brand assets.
- Reordering the team’s priorities from “more social proof” to “more complete story”, matching action to leverage in the funnel.
- Turning subjective debates into quantifiable gaps, enabling the team to discuss “where we’re behind” with numbers rather than opinion.
There is no fabricated claim here: we do not yet have post-optimization performance data for this listing. What changed, demonstrably, is the operating logic:
- The team stopped trying to brute-force their way to parity with reviews alone.
- They started building a listing that actually supports the kind of trust their competitor already earns through structure and storytelling.
For other brands reading this, the takeaway is not “you need A+ because everyone does.” It’s this:
> If you feel stuck blaming reviews, price, or “brand power”, you may be misdiagnosing the problem. > The real issue might be that your listing never gives buyers the full decision path your competitors quietly perfected.
DeepBI doesn’t make that decision for you. It shows you where the path is broken, how far behind you are at each step, and which fix actually changes the commercial outcome.
---