

This case comes from an Amazon seller in the UK marketplace, operating a wireless intercom headset system for film and video production, drone work, and event teams. On paper, the product looked solid: 4.4-star rating, more reviews than a key benchmark competitor, strong technical specs, and a listing score of 78/100. Yet Amazon ads were becoming harder to justify as ACOS pressure rose and click-to-order conversion stalled around a nearby benchmark that was clearly winning more buyers.
The seller’s internal diagnosis focused on “pushing the ads harder” and “maybe collecting more reviews.” Their assumption was that with more social proof and stable campaigns, conversion would naturally catch up. DeepBI was brought in not to rewrite ads, but to answer a simpler question: why was a technically competitive product with more reviews still losing at the product-page level?
DeepBI’s Listing scoring and competitor comparison made the pattern clear: this was not primarily an advertising failure. The Amazon Listing itself—title, main images, bullet-point logic, and A+ visual story—was under‑communicating professional value in a category where buyers are making high-risk, high-consideration decisions. The core issue was Listing conversion capacity, not traffic volume.
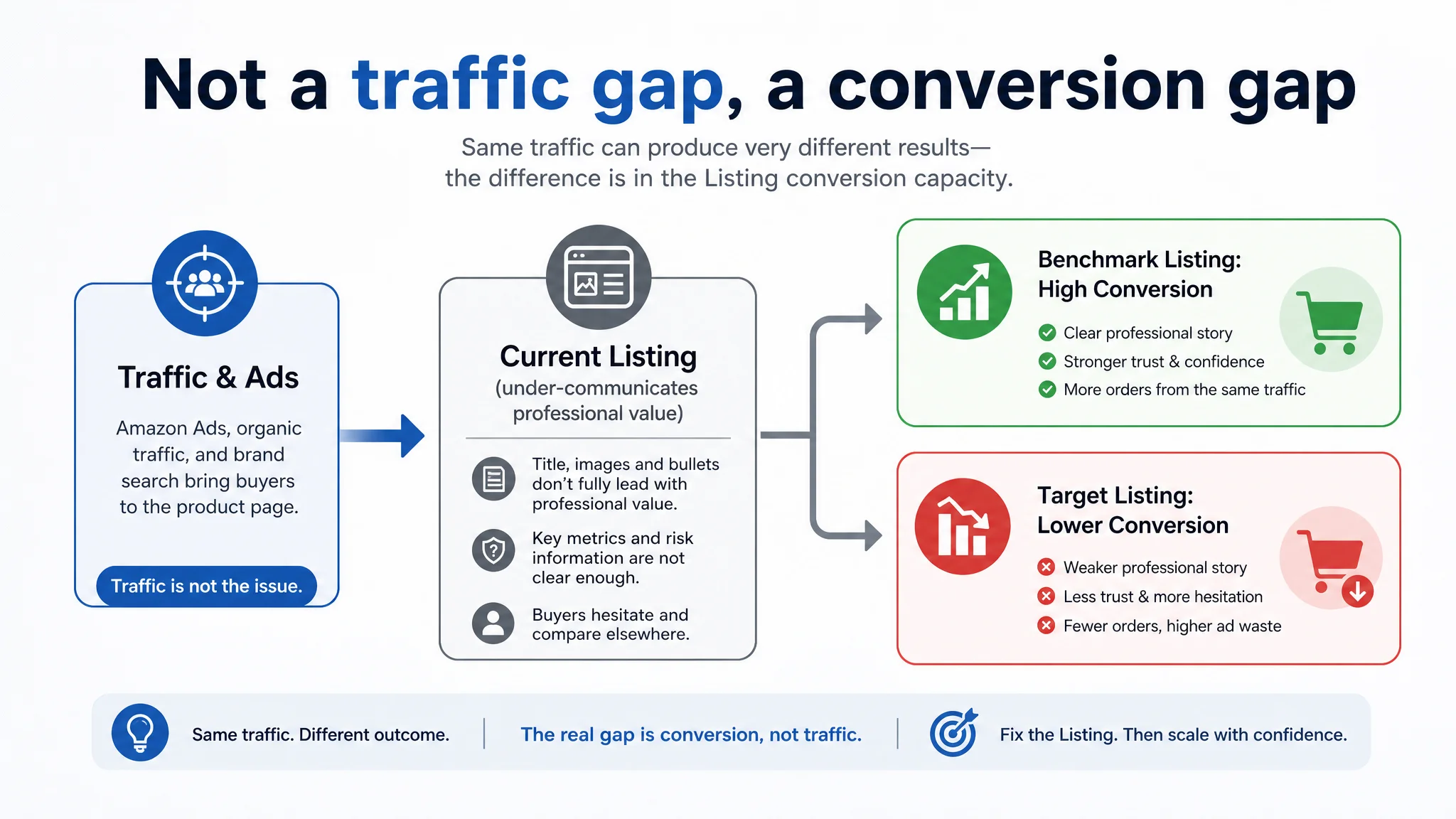
Once the problem was reframed this way, the optimization direction changed. Instead of “more reviews” or “more ad tests,” the focus moved to: a more targeted Amazon title, a main-image set that visually signals a professional, full system, bullet points that lead with operational advantages instead of raw specs, and A+ content that replaces generic scenes with quantified performance and professional film-set narratives. For other Amazon sellers, the lesson is blunt: even with good ratings and decent scores, a Listing that does not visually and structurally match how your best competitor de-risks the purchase will quietly consume your ad spend.
This Amazon Listing Did Not Lack Traffic. It Lacked a Convincing Professional Story.
From the seller’s perspective, the numbers did not look bad.
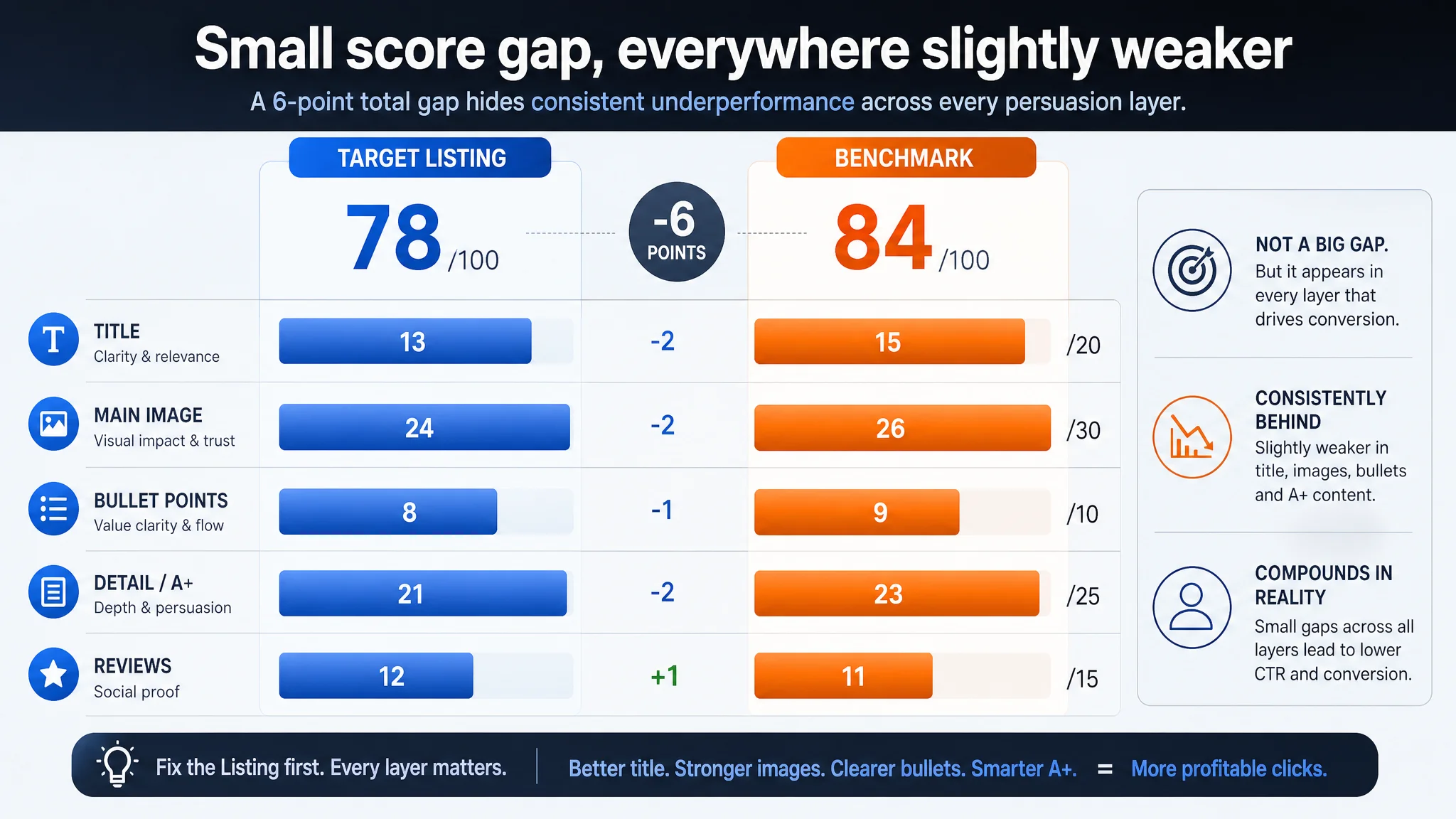
- Overall Listing score: 78/100
- Benchmark Listing score: 84/100 (a well-known wireless intercom system in the same UK category)
- Review rating: 4.4 vs 4.4
- Review count: the target Listing had about 50% more reviews than the benchmark
- Score by dimension:
- Title: 13 vs 15
- Main image: 24 vs 26
- Bullet points: 8 vs 9
- Detail/A+ content: 21 vs 23
- Reviews: 12 vs 11
Nothing here screams “disaster.” Yet in an increasingly ad-driven environment, the seller felt the pressure:
- Ads were not scaling efficiently.
- ACOS improvement stalled, even when bids and keywords were tuned.
- Benchmark competitors were defending price and winning more professional buyers.
Internally, the team concluded:
- “Our reviews are strong; the problem must be in ad optimization.”
- “Maybe we just need more social proof and slightly better creatives.”
- “The Listing is already decent; ad tuning should do the rest.”
“The real problem was not that ads failed to bring traffic. It was that the page could not convert the traffic with the same professional confidence as the benchmark.”
DeepBI’s job was to decide whether this was truly an ad-ops problem, or a Listing conversion problem hiding under stable review metrics.
The Real Constraint Was Listing Conversion Capacity, Not Social Proof
DeepBI’s Listing scoring compared the target Listing to a single, tightly matched benchmark intercom system—same use cases (film production, drone operations, team communication), similar price band, and similar technical category.
The 6-point total score gap was not random. It concentrated exactly where professional buyers make decisions:
- Title clarity and scenario anchoring
- Main-image set and visual trust
- Bullet-point logic (value-first vs spec-first)
- Detail/A+ content: quantified performance and system options
In other words, the product page did not fully reflect the product’s true strengths, especially versus a benchmark that had systematically turned each technical advantage into a clear commercial promise.
DeepBI’s judgment: fix the Listing first. Injecting more traffic into a page that is slightly but consistently outperformed on every persuasion layer only increases wasted ad spend.
Amazon Ads Were Not Failing. The Page Was Consuming the Traffic.
DeepBI’s diagnosis followed a simple funnel logic:
1. Traffic existed. The product had an established presence, with broad review volume and clear demand.
2. Ratings were healthy. 4.4 stars on both Listings meant no obvious trust collapse.
3. Benchmark performance gap appeared in the Listing structure, not in the rating layer:
- More data-driven, professional storytelling on the benchmark detail page
- Better scenario alignment in the title
- Stronger visual cues of “industry-validated” use in the main and A+ images
When ads push traffic into this kind of environment, one of two things happens:
- On the benchmark Listing, each click lands on a clear professional promise: quantified noise performance, clear range, transparent limitations (e.g., water resistance boundaries), and visible multi-user kit options.
- On the target Listing, each click lands on a more generic, softer story, with many scenes (sports, fishing, outdoor, weddings) but fewer hard technical anchors, and limited emphasis on system expansion and professional risk management.
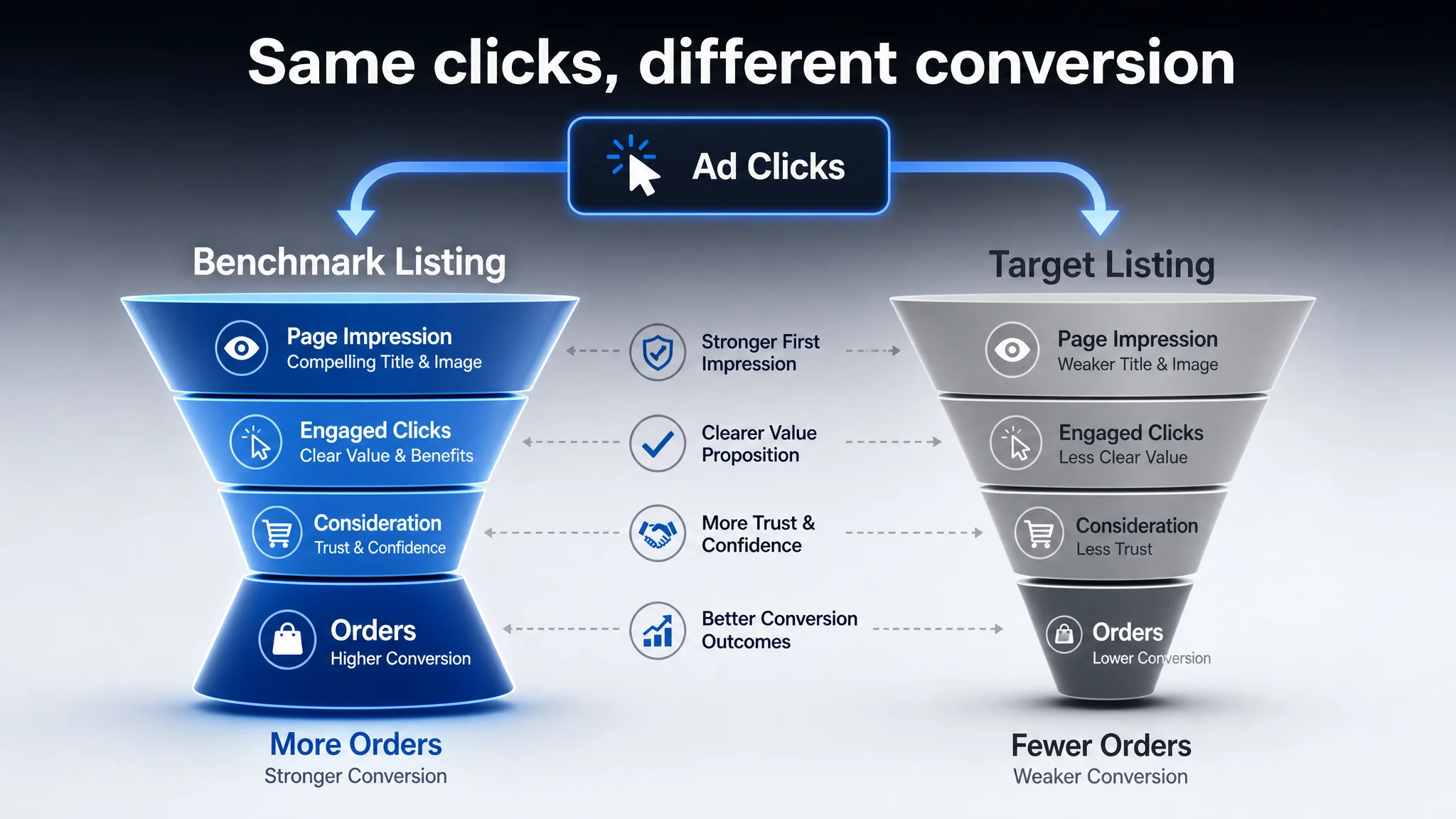
“Advertising does not only amplify advantages. It can also amplify a page’s existing defects.”
DeepBI’s conclusion: the ads were doing their job. The Listing was not fully catching the traffic.
Where the Title Lost Amazon’s Professional Buyer
The benchmark title front-loaded what professionals search and decide on
The benchmark’s Amazon title does four things with discipline:
1. Brand + Series + Category: establishes recognition and series identity.
2. User count and key technology up front
“2-User ENC Noise Cancellation Wireless Intercom Headset System”
1. Core range and communication mode
“350m Team Communication with PTT Mute”
1. Precise use scenarios
“for TV Film Production Drone (2.4G Version)”
A professional buyer on Amazon UK, searching for full-duplex, 2- or 5-person intercom systems, sees everything they need in the first scan: how many people, how quiet, how far, and in which context.
The target title underplayed its strengths and mis-ordered information
By contrast, the target Listing:
- Placed less critical information like “1PC” in a visible position, instead of anchoring on system use and professional outcomes.
- Did not fully exploit the product’s competitive advantages in the title:
- Longer range (up to 1,148ft/350m)
- Longer battery life (up to 24 hours)
- Strong film/video production scenarios
DeepBI’s recommended title structure:
“2.4GHz Full Duplex Wireless Intercom Headset System, 1148ft Range 24H Battery, Single-Ear Team Communication Headset for Film Production, Drone, Video Production”
This is not about keywords alone. It’s about mirroring how Amazon’s professional buyers interpret the search results page:
- Range and runtime front and center
- Full-duplex communication clearly stated
- Clear “team communication” and “film/drone/video production” alignment
- No distracting “(1PC)” signals that fight against perceived system value
By not leading with these strengths, the original title effectively made the product look less professional and less scalable than it really is, which directly undermines both CTR (click-through) and CVR (conversion).
The Main Image Set Looked Like a Consumer Gadget, Not a Professional System
On Amazon search results, the main image is rarely a design problem; it’s a decision problem. Professional buyers scanning intercom systems at similar prices gravitate toward:
- Full-kit presentations that signal “system-level” value
- Clean, data-backed graphics
- Authentic, real-world usage scenes that imply “industry validation”
How the benchmark main images signaled “system-level trust”
The benchmark’s main-image stack did several things better:
- Kit-centric primary image: a full set of headsets, batteries, and case laid out with clean composition—immediately reinforcing higher perceived ticket size and professional completeness.
- Icon + short copy data graphics: 2x3 or similar grids with icons, short labels, and key numbers, reducing cognitive load for busy buyers.
- Real work environments: staff wearing the system on active sets, real expressions, real movement—strongly suggesting the product is already in field use.
How the target main images diluted professional confidence
The target Listing’s main images:
- Used a white background hero shot with less precise kit composition. Accessories and batteries looked more “placed” than “engineered,” reducing perceived system rigor.
- Over-relied on dense text overlays and busy graphics, increasing reading cost and making the images feel more like consumer gadgets than professional tools.
- Included B2C-style lifestyle scenes (sports, fishing, outdoor) that are visually appealing but not directly tied to core professional decision logic for film and event crews.

DeepBI’s interpretation: this is not a taste issue; it’s a professionalization gap. The product is capable of sitting in a high-trust, professional category, but the visual language positions it closer to a general-purpose communication gadget.
The Bullet Points Had Information, but Not a Buying Logic
Both Listings used bullet points to explain features. The difference lay not in how much they said, but how they framed the story.
Benchmark: value summary first, promise second, specs last
The benchmark’s bullet points follow a clear ladder:
- Start with value phrases:
- “Seamless Team Talk & ENC Noise Cancellation”
- “Reliable Communication & Expandable Solution”
- “Superior Sound & Water and Wind Resistance”
- “Hassle-Free Operation & Lightweight”
- “Up to 12H Runtime & Replaceable Battery”
- Then support them with:
- Quantified metrics (e.g., 70dB SNR)
- Environmental boundaries (water/wind resistance)
- Explicit expansion (up to 5 headsets)
- Operational reassurance (ready-to-use, simple controls)
The result is a bullet set that reads less like a datasheet and more like a professional risk reduction script.
Target Listing: strong specs, but framed like engineering notes
DeepBI’s analysis of the target bullet points:
- Strong on technical detail (decentralized algorithm, dual-mic AEC, full-duplex, 350m range, 24h battery, domination mode).
- Weak on value-first framing:
- Leading with technical terms instead of clear benefits
- Combining multiple critical ideas into a single dense bullet (e.g., pairing “one-key pairing” and “battery life” together)
- Ending on “master control mute mode,” which signals advanced control but not everyday reassurance
To address this, DeepBI reorganized the bullet logic around five professional decisions:
1. System resilience & decentralization
Highlighting decentralized master-remote switching: if any headset fails, the system doesn’t collapse. This is mission-critical for film shoots and live events.
1. Range & reliability in complex environments
Framing 350m / 1,148ft as a coverage guarantee, not just a number—explicitly tied to large venues and complex RF environments.
1. Professional AEC noise reduction & clarity
Turning AEC and the 150Hz–7000Hz range into a clarity promise, linked to noisy weddings, racing, and crowded sets.
1. 24h ultra-long battery life & field replaceability
Making 24 hours and Type-C fast charging the day-long coverage promise, directly contrasting with shorter benchmark runtimes.
1. Domination mode & real-time monitoring
Presenting domination mode and 3.5mm monitoring as director tools, elevating perceived sophistication and professional control.
The key is not the text changes themselves. It’s the decision logic:
“Every bullet must correspond to a specific professional fear and close it.”
The Detail Page Did Not Lack Content. It Lacked Quantified Proof and System Pathways.
On A+ and detail content, both Listings were rich. The difference was what they chose to make visible.
Benchmark: data-backed professional reassurance
The benchmark’s A+ structure focused on:
- Noise and signal performance: e.g., “>70dB SNR”, explicit ENC labeling.
- Anti-interference and range: auto frequency hopping, clear distance statements.
- Water and wind resistance: not only claims, but explicit caveats (e.g., “not fully waterproof”) that signal honesty.
- Multiple kit options: “2–5 headset” configurations laid out as a clear upgrade path.
- Modular parts and packaging: consistent kit listing and replacement options.
This content transforms the page into a professional spec narrative. It allows buyers to justify their purchase internally: “We chose this because noise, range, environmental resilience, and expansion are all clearly specified.”
Target Listing: rich scenes, weak quantified anchors
The target detail page used a different strategy:
- Several visual modules:
- Core selling image
- Voice clarity
- Instant control and real-time monitoring
- Battery and pairing
- Comfort and accessories
- Multi-scene usage (sports, fishing, construction, outdoor shooting, weddings)
- Heavy emphasis on scene variety, lighter emphasis on numeric performance:
- No explicit noise metrics comparable to “>70dB SNR”
- No clear cut-off for water resistance or environmental limits
- No “Multiple options for every need” section that clarifies 2–5 user configurations

DeepBI’s conclusion: for this category, Amazon buyers are not seeking “visual lifestyle breadth” alone. They want a professional, quantifiable assurance chain.
“Without quantified performance and explicit system options, a rich A+ page still fails to convert professional anxiety into confidence.”
Why DeepBI Did Not Recommend “Fix Ads First”
Many Amazon sellers, facing similar numbers, choose to:
- Test more creatives in Sponsored Brands or Sponsored Products
- Shift bids and match types
- Increase budget caps in peak periods
- Chase more reviews to “catch up” with competitors
DeepBI explicitly chose the opposite order.
The biggest risk: amplifying a slightly weaker Listing with more paid traffic
At 78/100 vs 84/100, the target Listing is not broken—but it is systematically slightly worse at each persuasion layer that matters for high-consideration purchases. In such cases, adding more traffic:
- Increases wasted ad spend on clicks that are already half-convinced
- Makes ACOS harder to compress, because the page itself is not fully persuasive
- Gradually erodes confidence in ad operations, when the real problem lies in the page
DeepBI’s judgment chain:
1. The Listing is not fully leveraging its strengths (24h battery, decentralized architecture, strong AEC, wide frequency range).
2. Competitors are turning their strengths into clear, quantifiable promises.
3. The page’s current conversion capacity is the bottleneck for both organic and paid traffic.
4. Therefore, Listing repair is the correct first move, before scaling ads.
How the Page’s Sales Logic Started to Recover
DeepBI’s optimization plan did not revolve around “making things prettier.” It was about aligning every major module with professional decision logic.
1. Main image: from “gadget” to “professional kit”
- Recompose the primary image to show:
- Headset + batteries + cables + key accessories in a 70% central kit layout
- 45° angle hero shot with controlled shadows and a cool, tech-oriented palette
- Replace dense overlay text with:
- Clean, icon-based callouts
- A matrix-style feature graphic with short, value-led labels
- Introduce:
- A real operator wearing the headset in a film set environment
- A dedicated image highlighting “3.5mm TRS Real-time Monitoring”
- A clear action image showing a battery being swapped mid-operation
- A noise reduction image with waveform visualizations and “AEC Noise Reduction”

2. Title: from technical label to search-entry narrative
- Move range, battery duration, and full-duplex communication into the front half of the title.
- Add Film Production, Drone, Video Production explicitly, aligning with how Amazon’s algorithm and users interpret intent.
- Remove confusing “(1PC)” cues that undercut perceived system completeness.
3. Bullet points: from spec list to risk-control sequence
- Reorder bullets to match:
1. System resilience (decentralized master-remote switching)
2. Range and signal reliability
3. Professional noise control and clarity
4. Battery endurance and replaceability
5. Command and monitoring for directors
Each bullet now answers a specific professional concern: “Will it fail mid-shoot?”, “Will it cover the venue?”, “Will we hear clearly in noisy environments?”, “Will battery be a problem?”, “Who’s in control on set?”
4. Detail/A+ content: from scattered scenes to quantified professional proof
DeepBI’s A+ recommendations focused on:
- Core clarity module: cinematic dark-tone image with real filming scene, overlaid waveform graphics and key metrics like “>70dB SNR” and “AEC noise reduction”.
- Range module: a stadium or open-field shot with large, central “350M / 1100FT” typography, making distance the visual anchor.
- Battery module: a split image showing removable batteries and an outdoor sunset shoot, with “24H Working Time” as the visual focal point.
- Comfort module: macro shots of ear cushions and materials, emphasizing long-wear comfort.
- Outdoor reliability module: water-side or kayak scenario, with visually implied environmental resilience without over-claiming waterproofing.
- Multi-scene composite: structured panels for “Artistic Production”, “Commercial Filming”, “Outdoor Events” with consistent filmic style.
- Package & configuration module: clean, overhead layout of all items with precise label lines and quantities—reducing pre-sale friction and post-sale uncertainty.
Together, these changes shift the Listing from “rich but generic” to “rich and explicitly professional.”
How Ad Traffic Became Useful Again
Because this case centers on Listing analysis, not ad log data, we do not inject invented metrics. Instead, we look at operational state changes that this optimization enables:
- CTR support: A more compelling title and kit-centric main image give ads a stronger chance of earning the click in crowded Amazon search results.
- CVR foundation: Clearer bullet logic and quantified A+ content reduce professional buyer hesitation—especially regarding range, noise performance, and battery risk.
- Ad spend stability: Once the page converts more like the benchmark, each paid click carries less waste, making ACOS more responsive to bid changes.
- Organic resilience: As conversion improves, the Listing becomes less dependent on aggressive ad budgets to maintain its ranking and sales velocity.
The critical shift is not only in metrics, but in how the seller judges problems:
- From “Our ads aren’t strong enough”
- To “Our Listing was under-communicating professional value and risk control.”
What Other Amazon Sellers Can Learn from This Case
This case is not about a specific wireless intercom system. It is about how easily Amazon sellers misdiagnose conversion problems as ad problems.
Key lessons:
1. Healthy reviews do not guarantee a healthy Listing.
A 4.4-star rating with more reviews than a competitor can still hide a weaker professional story in title, images, bullets, and A+.
1. Benchmarking must go beyond aesthetics.
The benchmark Listing won because it quantified critical metrics (noise, range, runtime, environmental limits) and made system options explicit.
1. Listing conversion capacity sets the ceiling for ad efficiency.
No matter how refined your campaign structure is, a slightly weaker Listing will consume traffic without returning the same revenue per click.
1. Professional categories need professional narratives.
In high-decision-cost categories like communication systems, buyers need quantifiable evidence and clear risk boundaries—not only scenes and lifestyle imagery.
1. Fix the page before scaling the ads.
If a DeepBI-like diagnosis shows consistent gaps vs a single, well-matched benchmark, it is almost always safer to repair the Listing first, then push more traffic.
In this Amazon seller’s case, DeepBI’s value did not come from generating more variations of creatives or suggesting more A/B tests in the ad console. It came from identifying that the real business constraint was the Listing’s ability to translate a technically strong product into a clearly superior professional choice—so that every future click, organic or paid, finally had a page worth landing on.